
The Partial Sophistication Trap: What 332,557 Emails Taught Me About Context Architecture

The simulation is done. The results are in. And the most important finding is not what I expected.
A few weeks ago I published an essay called “The Context Bank” arguing that organizations are building the wrong layer of the context stack. They are buying feeds when they should be building lockers. They are optimizing for delivery when they should be optimizing for sovereignty.
That essay was the thesis. What I have been building since is the proof.
I built a simulation. A synthetic organization, Acme Advisory, a ninety-person consulting firm, running across twelve weeks of operations, with four AI agents making decisions in procurement, staffing, proposals, and billing. I seeded the simulation with the kind of institutional memory that lives in organizations but never makes it into documentation: the vendor that requires secondary approval because of a billing dispute two years ago, the client whose payment cycle is 60 days regardless of what the contract says, the staffing conflict that HR knows about but the system does not surface.
Then I ran four experimental conditions representing the adoption trajectory an enterprise actually follows as it builds toward context sophistication.
SILOED_TYPICAL: Each agent sees only its own department’s context. No retrieval sophistication.
SILOED_ADVANCED: Agents see adjacent departments, attempt context retrieval, apply basic decay.
GLOBAL_RAG: Full organizational visibility, retrieval-augmented generation, no primitive sophistication.
CONTEXT_BANK: Full visibility plus the complete primitive stack: confidence scores, decay functions, provenance chains, validation propagation.
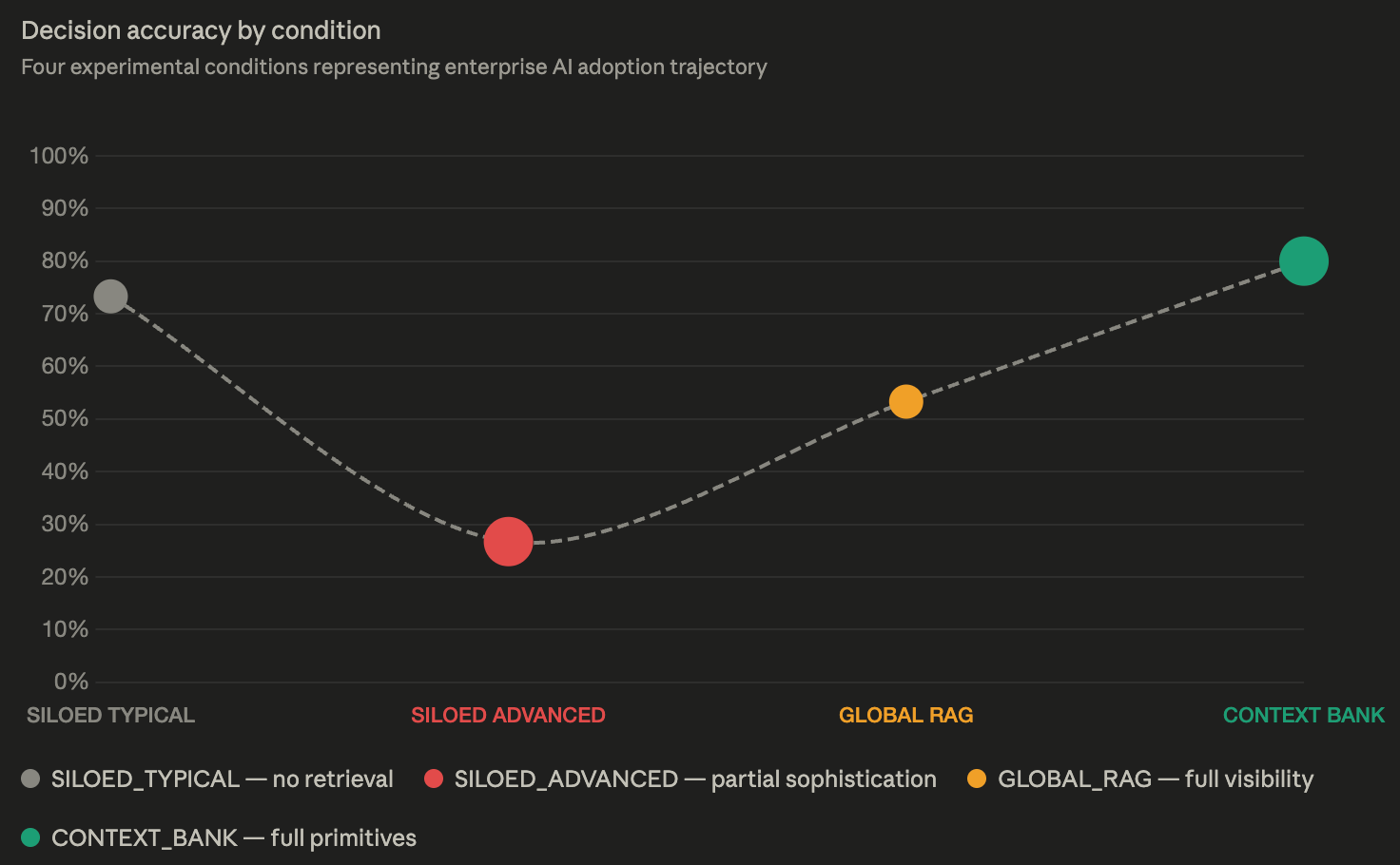
Read that again. SILOED_ADVANCED, the condition with more sophistication than baseline, performed 46 points worse than the condition with no sophistication at all.
This is the finding I did not expect, and it is the most important thing I learned from the simulation.
The Partial Sophistication Trap
Here is what is happening.
SILOED_TYPICAL makes decisions using base heuristics. It does not attempt context retrieval. It has no retrieval failures because it attempts no retrieval. It is organizationally naive, but it is consistently naive.
SILOED_ADVANCED attempts to be smarter. It retrieves context. It applies decay. It looks for relevant institutional memory. But it has partial visibility and partial sophistication. It retrieves without the mechanisms that would tell it what to trust, what has been validated, what contradicts what.
The failure modes multiply:
P(correct) = P(retrieval) x P(interpretation) x P(visible) x P(base_decision)
For cross-domain scenarios where the relevant context lives in a department the agent cannot see:
0.85 x 0.90 x 0.0 x 0.62 = 0%
Zero. The agent retrieves, interprets, and acts confidently, on incomplete information, in exactly the scenarios where institutional memory matters most.
This is the trap. A system that partially attempts context retrieval without the full primitive stack fails more confidently than one that makes no attempt at all. SILOED_ADVANCED knows it should use context. It tries. It fails in ways that SILOED_TYPICAL never could, because SILOED_TYPICAL was never trying in the first place.
Organizations building toward context sovereignty through incremental feature addition will pass through a performance trough that is worse than their starting point. The only exit from the trough is the complete primitive stack.
Half-measures are not a path to the destination. They are a detour through degraded performance.
The Context Bank works because confidence, decay, provenance, and validation are not features you add on top of a retrieval system. They are the primitive itself. You cannot get the benefit of one without the others because the benefit comes from their interaction.
Why This Matters for Every Enterprise AI Deployment
Every enterprise AI vendor is shipping some version of SILOED_ADVANCED right now.
“We added RAG to our agents.” “We have vector search and retrieval.” “Each agent manages its own context window.”
They are in the trap. Their customers are experiencing worse outcomes than before they added AI context capabilities, and nobody has a framework to explain why.
The primitive stack is not composable from parts. Confidence without decay is noise. Decay without validation is arbitrary. Retrieval without provenance is gambling. You need all of it, or the partial implementation introduces failure modes without providing the synthesis to overcome them.
This is Chesterton’s Fence applied to AI architecture. Do not partially add sophistication until you can add it completely.
The Enron Calibration
The simulation needed realistic inputs. I calibrated the behavioral exhaust stream against 332,557 real organizational emails from the CMU Enron corpus, 500,000+ emails from 150 senior employees, parsed for knowledge transfer patterns, seniority signals, exception handling discussions, and approval chain references.
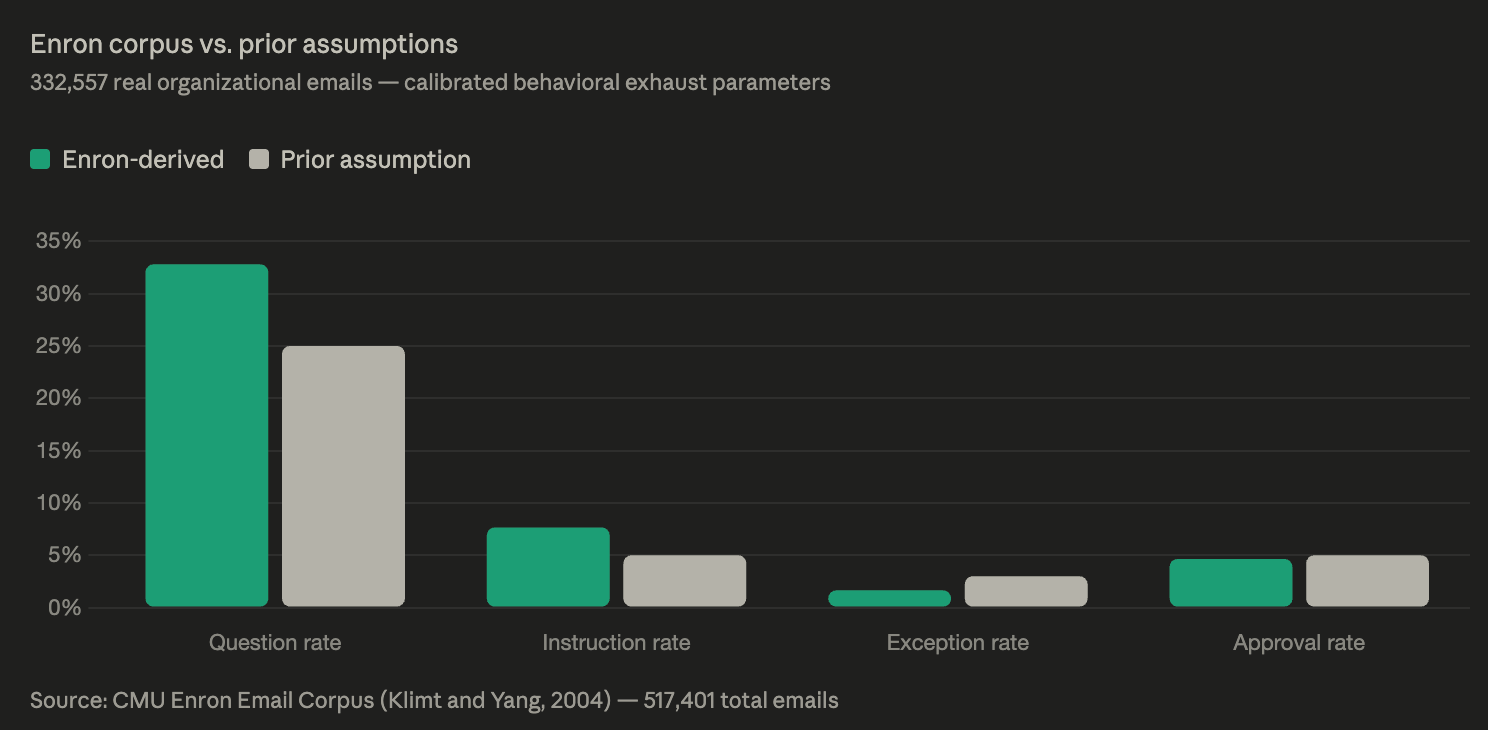
What I learned: organizations ask more questions than I assumed (33% vs my initial guess of 25%), transfer more explicit instructions (7.7% vs 5%), and discuss exceptions less frequently (1.65% vs 3%). Real organizational communication is also far more verbose than I modeled, 1,728 characters average versus my initial 500.
The Enron calibration is not just a credibility signal. It is the difference between “I built a toy” and “I built a simulation grounded in how organizations actually communicate.”
What Comes Next
I have submitted a formal paper to SSRN specifying the Context Object primitive, the six dimensions that make it categorically distinct from existing database primitives, and the full simulation methodology. I will share the link when it is live.
The simulation code is available upon request. Reach out at madhu.kashyap@gmail.com.
But the simulation is not the proof. The simulation validates that the primitive behaves consistently with the proposed mechanics under controlled conditions. The proof requires a real deployment.
I am working to line up the first organization willing to run this. A design partner with real agent workflows, real institutional memory worth preserving, and a willingness to instrument the three exhaust streams, agent, structured, behavioral, and measure what happens.
If that is interesting, please reach out.
The first essay in this series laid out the thesis. This one shares what happened when I tested it.